2.9 Connections
Wirings between Transformer inputs and outputs.

Diagram 2.9.0: The Transformer, Vaswani et al. (2017)
Encoder-decoder architecture
An initial glimpse of the Transformer may raise questions regarding why both encoder and decoder have inputs. This is not made entirely clear in the original Vaswani et al. (2017) paper. The following diagrams depict why - the decoder blocks take as input the encoded initial input sequence, as well as the generated tokens that the Transformer itself has generated, and continue to feed newly generated tokens back into the decoder until the output sequence is finished.
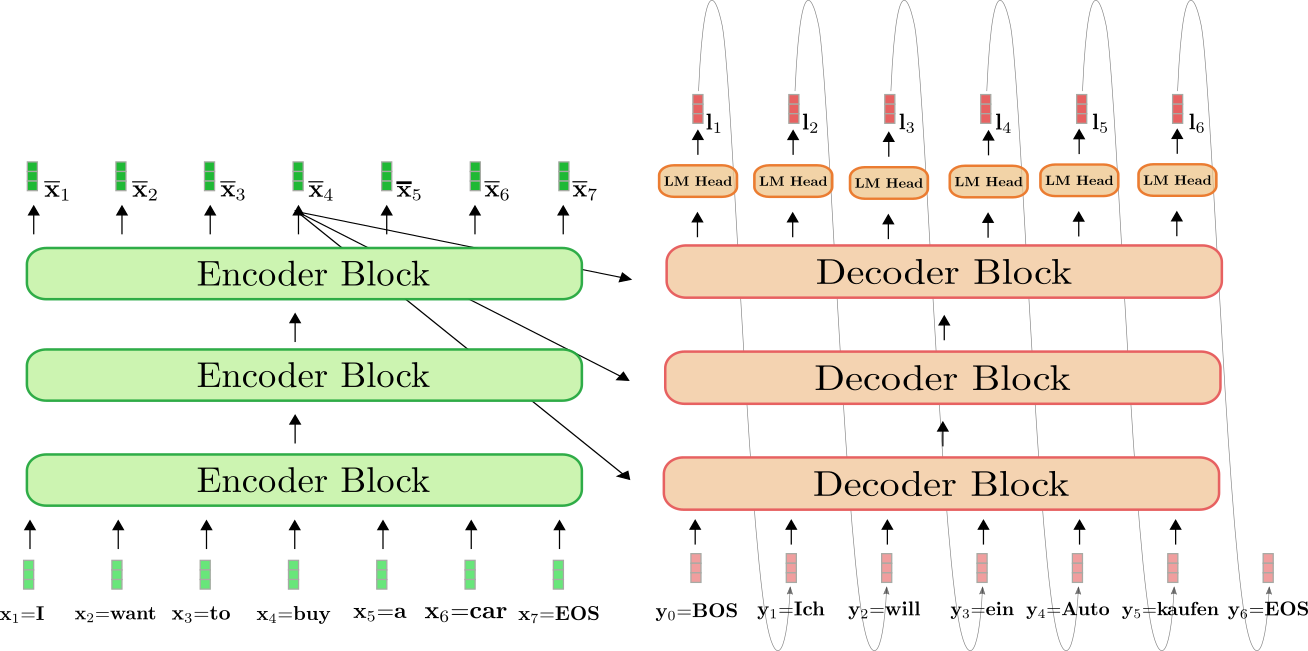 Diagram 2.9.1: an LLM performing a machine translation task, note that this model features stacked encoders and decoders, not uncommonly. The LM Head is made up of the Linear and Softmax layers. Source: HuggingFace blog
Diagram 2.9.1: an LLM performing a machine translation task, note that this model features stacked encoders and decoders, not uncommonly. The LM Head is made up of the Linear and Softmax layers. Source: HuggingFace blog
Note that Transformers are typically stacked, and the logic behind this is akin to adding more layers to a neural network; it is expected that accuracy of predictions will increase as processing of the data increases.
Decoder only architecture
 Diagram 2.9.2: An example of 4 decoders stacked together.
Diagram 2.9.2: An example of 4 decoders stacked together.
The original Vaswani Transformer research paper stacked 6 identical decoders together.[1] Note that the Linear and Softmax layers are not stacked, they only occur once for each token generated.[2]. In a modern LLM, many Transformer decoder layers are stacked together, as in Diagram 2.9.2. Llama-4, in the default configuration, stacks 48 decoders together. In the context of a model based upon a Transformer, each decoder may be referred to as a hidden layer.
As previously mentioned in the attention head section, a Transformer can actually input multiple tokens in one go, and this allows weights to be optimised at scale during training. The Llama-4 default is of 131,072. During utilisation, however, only the initial prompt can be input in one go, and so, the output of the Transformer has to be fed back as input, as in Diagram 2.9.3. Eventually a symbol will be output by the Transformer that indicates that the generation sequence has ended. A cache within the attention layers can allow previously calculated values of q, k, and v, to be reused.[2]

Diagram 2.9.3: A set of stacked Transformers taking as input an input sequence and generating tokens successively.
Note that many mainstream LLMs may be trained to react to any input sequence with a conversational style (e.g. by using conversational style training data), regardless of the input. However, it is alternately possible to train an LLM to directly finish off sentences.
References
[1] Attention Is All You Need, 3.1 [2] Speech and Language Processing, Chapter 8.5; Transformers